Zahvala Kazalo Seznam uporabljenih kratic in simbolov 1 Povzetek 2 Abstract 3 Uvod 4 Opis problema 5 Načrt sistema 6 Podatkovni model 7 Geokodiranje 8 Nasprotno geokodiranje 9 Usmerjanje 10 Izkušnje in nadaljnje delo 11 Sklep Dodatek A Navodila za uporabo sistema Literatura
- Naslov
- Razvoj naprednih storitev za GIS
- Del
- 5 Načrt sistema
- Datum vsebine
- 23. 11. 2010
- Original
- RazvojNaprednihStoritevZaGIS.pdf
- Vrsta
- diplomska naloga
- Jezik
- slovenščina
- Različica
- 1.0
- Ustanova
- Fakulteta za računalništvo in informatiko, Univerza v Ljubljani
- Študij
- Univerzitetni, računalništvo in informatika, logika in sistemi
- Predmet
- -
- Mentor
- doc. dr. Mojca Ciglarič
- Avtor
- Tine Lesjak
- Ocena
- 10 od 1-10
Gre za celotno diplomsko delo s predstavitvijo.
Dodatne objave dela:
- ePrints.FRI: ID 933
- COBISS: ID 7349844
- predstavitev.pdf
- Predstavitev diplomskega dela na zagovoru (dne 22. 10. 2009).
- projekti.zip
- Vsa izvorna koda v obliki SpringSource Tool Suite projektov (združljivi z Eclipseom) pod licenco Creative Commons Attribution 2.5 Slovenia License
- primeri.zip
- Primeri, predstavljeni kot izvlečki kode v diplomskem delu.
- tinel-gis-geocoding.war
- Storitev geokodiranja.
- tinel-gis-reversegeocoding.war
- Storitev nasprotnega geokodiranja.
- tinel-gis-routing.war
- Storitev usmerjanja.
V tem poglavju si bomo ogledali, kaj vse sistem zaokrožuje, vsebuje in na kakšnih tehnologijah so zgrajeni njegovi temelji. Predvsem kratek uvod v posamezno uporabljeno tehnologijo je pomemben, če želimo razumeti algoritme posamezne storitve in če morebiti želimo sistem vključiti v svojega lastnega.
5.1 Sestava
Sistem je sestavljen iz štirih glavnih komponent:
- podatkovnega modela,
- storitve geokodiranja,
- storitve nasprotnega geokodiranja in
- storitve usmerjanja.
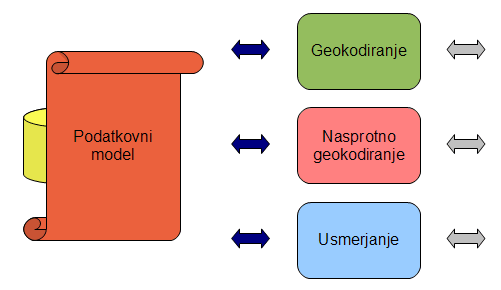
Slika 5.1: Sestava sistema.
Vse storitve so prilagojene za podatkovni model in so zato od njega tudi odvisne. Vsako komponento sem posebej podrobno opisal v naslednjih poglavjih.
Kljub temu, da sistem združuje več komponent, je še vedno le del celotne uporabniške izkušnje. To bi lahko razdelili na vsaj tri dele. Prvi je odjemalec za prikaz podatkov, s katerim uporabnik krmili in opazuje ves sistem. Ta je neposredno odvisen od storitev (drugi del), ki jih nudi strežnik. Strežnik uporabniške ukaze izvaja nad podatki, ki predstavljajo tretji del.
Sistem povsem zaokrožuje drugi del uporabniške izkušnje, do celote mu manjkajo podatki in implementacija na strani odjemalca. Oboje sem za uspešno testiranje in opravljanje meritev zmogljivosti potreboval.
Dodatno sem razvil grafičnega odjemalca za testiranje, ki nazorno prikazuje zmogljivost sistema, rabi pa tudi kot primer uporabe sistema na uporabniški strani.
5.2 Tehnologije
Vsak sistem je skupek tehnologij, ki so že razvite in zelo olajšajo in skrajšujejo razvoj potrebnih funkcij, ki so ponavadi za razvijalce precej suhoparne. Bistveno pri tem pa je, da uporaba zrelih tehnologij zelo zmanjšuje možnost vnosa človeških napak v sistem.
V sistemu so uporabljene zelo pestre tehnologije. Vse so sodobne, celo zelo nove, a preverjene.
Programski jezik je Java. Je objektno usmerjen, moderen, razmeroma preprost, varen in nevtralen do platforme [4]. Java je tudi najbolj priljubljena izbira med programerji [21] in na koncu koncev je priporočena s strani podjetja. Nekaj skript je napisanih v javi sorodnem skriptnem programskem jeziku Groovy.
Sistem potrebuje podatkovno zbirko (angl. database), ki omogoča hranjenje in analizo nad geografskimi podatki. Uporabljena je običajna relacijska podatkovna zbirka PostgreSQL, ki skupaj z dodatkom za geografske podatke PostGIS, standardizira obdelavo prostorskih podatkov. PostGIS je najbolj smotrna izbira, saj je zastonj, preverjena in funkcionalno ne zaostaja za velikimi. Prostorski podatki so zahtevnejši od običajnih, saj nastopajo v več dimenzijah (običajno v dveh, lahko pa z dodatnim podatkom o višini tudi v treh). Indeksira se jih s posebno vrsto indeksa, ki se imenuje GiST (Generalized Search Tree). GiST ima to lastnost, da lahko indeksira nenavadne podatke, med njimi tudi večdimenzijske prostorske podatke.
Vez med aplikacijo in podatkovno zbirko je v javinem svetu tako imenovan gonilnik, spisan v programskem vmesniku JDBC (Java Database Connectivity). Komunikacija z zbirko je prek JDBC rahlo zapletena in razvoj zamuden, zato se danes uporabljajo višje nivojske tehnologije. Zelo primerna je tehnologija preslikave relacijskih podatkov v objekte, ki so običajni v objektnih programskih jezikih. Tehnologija ORM (Object-Relational Mapping), resnično, skoraj do skrajnosti, poenostavi delo s podatki v relacijski podatkovni zbirki.
Uporabil sem preizkušeno knjižnico Hibernate, ki svoje naredi tudi s posebnim poizvedovalnim jezikom HQL (angl. Hibernate Query Language), ki je objektno usmerjen.
Kako ORM deluje, je najbolje prikazati na primeru.
Recimo, da imamo preprost razred v javi, ki definira objekt Student:
public class Student {
private Long id;
private String name;
public Long getId() {
return this.id;
}
public void setId(Long id) {
this.id=id;
}
public String getName() {
return this.name;
}
public void setName(String name) {
this.name=name;
}
}Koda 5.1: Preprost razred Student v javi.
Objekt je enostaven, brez konstruktorjev s parametri in omogoča zunanji dostop do lastnosti prek getterjev in setterjev. Takšnemu objektu pravimo zrno (angl. JavaBean[*] oz. krajše kar bean) in je tipičen predstavnik POJO (Plain Old Java Object) [8] [9].
- *
- JavaBean (in POJO) je po dogovoru objekt, ki ga je možno serializirati. Objekt, podan v primeru, ni takšen.
V relacijski podatkovni zbirki pripravimo entiteto (tabelo) Student, ki ima naslednja atributa (stolpca):
- id kot primarni (indeksiran) ključ in
- name kot niz znakov.
Poizvedba HQL, s katero bi iz baze pridobili vse študente z imenom "Janez", je preprosta:
from Student where name='Janez'Koda 5.2: Poizvedba HQL, ki najde vse študente z imenom "Janez".
Njen ekvivalent v jeziku SQL, bi bil:
select * from Student where name='Janez'Koda 5.3: Poizvedba SQL, ki najde vse študente z imenom "Janez".
V pomnilnik aplikacije pa bi se naložili ob klicu:
List<Student> students=session.createQuery("from Student where name=?")
.setString(1, "Janez").list();Koda 5.4: Nalaganje študentov z imenom "Janez" iz podatkovne zbirke v pomnilnik aplikacije s pomočjo poizvedbe HQL.
Tako imamo v seznamu students vse podatke o študentih Janezih, ki se nahajajo v bazi, ne da bi se ukvarjali s komunikacijo z zbirko ali pretvarjanjem entitet v objekte. To za nas stori Hibernate, pri tem pa uporablja vrsto zanimivih funkcij, kot je predpomnilnik (angl. cache), tako da je hitrost na zavidljivi ravni in vsekakor višja, kot če bi razvijalec podobno poskusil izvesti sam prek JDBC-ja.
Definirati moramo še preslikavo objektov v entitete, tako da Hibernate natančno ve, s kakšnimi tipi podatkov ima opravka in kako so objekti oz. entitete med seboj povezani. To lahko storimo na dva načina: preslikave podamo v datoteki XML ali jih neposredno označimo na objektih. Slednje je z novejšo tehnologijo oznak v javi (Java Annotations) zelo prikladno. Vsak način ima svoje dobre in slabe lastnosti. V sistemu se uporabljajo oznake, ki so večinoma definirane v vmesniku JPA (angl. Java Persistence API), nekaj pa je lastnih Hibernateovih. Oznake imajo to dobro lastnost, da na morebitne napake ali nevarnosti opozori že prevajalnik oz. že razvojno okolje.
Objektu Student bi takole označili preslikovanje:
@Entity
public class Student {
@Id
@GeneratedValue(strategy=GenerationType.IDENTITY)
private Long id;
@Column
private String name;
// ...
}Koda 5.5: Preslikovanje razreda Student v entiteto. Getterji in setterji so izpuščeni, ker so enaki kot pri kodi 5.1.
Ker sistem dela s posebnimi podatki - geografskimi, zanje Hibernate nima pripravljenih funkcij za preslikovanje. Zanje obstaja knjižnica Hibernate Spatial, ki se postavi med PostgreSQL JDBC gonilnikom in Hibernateom kot posebno narečje zbirke.
Dober sistem mora nujno imeti učinkovito, preprosto in pregledno zasnovo, da je skupek vseh tehnologij in lastne programske kode sploh obvladljiv. Tukaj na pomoč priskoči odlično ogrodje Spring Framework, ki deluje kot močno in stabilno lepilo. Njihova tehnologija omogoča, da lahko vse programske dele aplikacije preprosto povežemo skupaj z eno datoteko XML. Pri tem je pomembno le, da je vsak programski del, na najnižjem nivoju je to objekt, napisan na preprost način, v obliki zrn, kot je, npr., naš Student. V datoteki XML definiramo tudi lastnosti posameznih zrn, ki se vstavijo (temu pravijo Dependency Injection) šele po njihovi tvorbi (kar je ravno obratno od vstavljanja lastnosti ob tvorbi s konstruktorjem, zato temu pravijo Inversion of Control) [23].
Skrajno enostavna datoteka XML bi izgledala takole:
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans-2.5.xsd">
<bean id="janez" class="Student">
<property name="id">
<value>512</value>
</property>
<property name="name">
<value>Janez Krajnski</value>
</property>
</bean>
</beans>Koda 5.6: Zrno janez v Springovi datoteki XML, ki predstavlja eno instanco objekta Student z ID-jem 512 in imenom "Janez Krajnski".
Rezultat njene uporabe v ogrodju Spring pa bi bila ena instanca objekta Student z ID-jem "512" in imenom "Janez Krajnski".
Knjižnica Spring ima prvorazredno podporo ravno za Hibernate, zato je delo z njim tako rekoč nezaznavno. Celotno konfiguracijo lahko opišemo v eni datoteki XML in že imamo podporo za dostop do baze DAO (Database Access Object). Neznanka session v primeru nalaganje vseh študentov (koda 5.4) tako hitro postane le ena izmed zrn, dodatna podpora DAO (HibernateTemplate) pa še vse skupaj poenostavi:
List<Student> students=getHibernateTemplate().find(
"from Student where name=?", "Janez");Koda 5.7: Nalaganje študentov z imenom "Janez" iz podatkovne zbirke v pomnilnik aplikacije s pomočjo poizvedbe HQL in Springove podpore DAO (HibernateTemplate).
Ogrodje Spring priskoči na pomoč tudi pri povezavi med odjemalcem in strežnikom. Povezava je narejena s tehnologijo HTTP Invoker. Ta je zelo podobna javini (Sunovi) lastni tehnologiji RMI (Remote Method Invocation), omogoča pa klicanje metod na daljavo tako, da sploh ne opazimo, da je določena metoda na drugi strani omrežja. HTTP Invoker pred klicem oddaljene metode morebitne parametre serializira (angl. serialize), to je pretvori v nezamenljiv niz zlogov, in jih pošlje v obliki zahteve (angl. request) prek standardnega spletnega protokola HTTP (Hypertext Transport Protocol). Strežnik metodo izvede in v odgovoru (angl. response) vrne njene morebitne rezultate (serializirane). Ker HTTP Invoker uporablja protokol HTTP, so morebitne motnje na omrežju nezaznavne, tudi ob prekinitvi povezave zna HTTP Invoker samodejno vzpostaviti novo. Dodatna prednost uporabe HTTP-ja je tudi ta, da gre za enega najbolj uporabljanih protokolov (brskanje po spletnih straneh), zato so po navadi požarni zidovi do njega prizanesljivi.
Če na kratko povzamem; med aplikacijo in podatkovno zbirko sistem uporablja celo vrsto tehnologij, ki skrajno poenostavljajo delo s podatki. Tako se lahko programer bolje osredotoči na sam problem, ki ga želi rešiti. Nivoji so naslednji:
- PostgreSQL
- PostGIS
- PostgreSQL JDBC (gonilnik)
- Hibernate Spatial
- Hibernate
- Spring Framework
- Zrno (objekt)

Slika 5.2: Nivoji tehnologij v sistemu od podatkovne zbirke (zgoraj) do domenskih objektov (zrna).
5.3 Okolje
Za razvojno okolje (angl. Integrated Development Environment - IDE) sem na koncu uporabljal brezplačno orodje SpringSource Tool Suite (STS), ki je maksimalno prilagojeno uporabi ogrodja Spring (izdelovalec ogrodja je podjetje SpringSource). Temelj STS-ja je platforma Eclipse.
V veliko pomoč pri razreševanju odvisnosti od knjižnic (pravijo jim dependencies) je bilo orodje Apache Maven.
Za testiranje sem uporabljal ogrodje JUnit, ki je preprosto in že vgrajeno v STS.
Vsa orodja so brezplačna za osebno in komercialno rabo, večina je odprtokodnih. Nobeno od orodij ni vezano na vrsto operacijskega sistema, pač pa na inačico javinega pogonskega okolja.
Celoten sistem je spisan v programskem jeziku Java, različice 6.0, zato za pogon (angl. runtime environment) potrebuje JVM (Java Virtual Machine) različice vsaj 1.6. Nekaj skript je napisanih v skriptnem programskem jeziku Groovy, različice 1.6, ki pa so namenjene samo začetni konfiguraciji sistema.
Strežniški deli (storitve) za delovanje potrebujejo vsebnik (angl. servlet container), saj so spisane v obliki spletnih aplikacij. Dva najbolj znana sta Apache Tomcat in Mortbay Jetty. Slednji se v vdelani (angl. embedded) obliki uporablja tudi pri testiranju storitev.
5.4 Paketi
Celoten sistem je sestavljen modularno iz treh končnih paketov, vsak paket predstavlja svojo storitev. Vse tri storitve so odvisne od knjižnic (angl. library, dependency), med katerimi so tudi lastne. Med njimi ena vsebuje vse o podatkovnem modelu. Ostale knjižnice so od zunanjih razvijalcev, vse pa so brezplačne.
Seznam končnih paketov, strežnikov storitev, ki se neposredno poženejo v okolju:
- tinel-gis-geocoding-server - vsebuje storitev geokodiranja
- tinel-gis-reversegeocoding-server - vsebuje storitev nasprotnega geokodiranja
- tinel-gis-routing-server - vsebuje storitev usmerjanja
Vsi strežniki implementirajo vmesnike storitev, ki jih izrabljajo odjemalci:
- tinel-gis-geocoding-client - vsebuje vmesnike storitve geokodiranja
- tinel-gis-reversegeocoding-client - vsebuje vmesnike storitve nasprotnega geokodiranja
- tinel-gis-routing-client - vsebuje vmesnike storitve usmerjanja
Vsi paketi poleg definicij storitev za odjemalce za delovanje potrebujejo še lastne knjižnice:
- tinel-commons - splošna lastna orodja
- tinel-gis-common-server - splošna orodja za strežnike
- tinel-gis-common-client - splošna orodja za odjemalce
- tinel-gis-model - podatkovni model (preslikava ORM, DAO)
Celoten sistem je torej sestavljen iz desetih lastnih paketov.
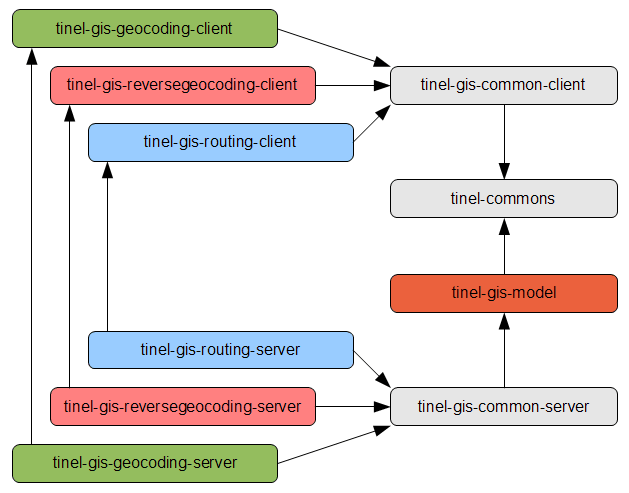
Slika 5.3: Paketi, iz katerih je sestavljen sistem. Zgoraj so paketi, ki jih potrebujejo odjemalci, spodaj so implementacije strežniških storitev.
Dodatno sem za potrebe testiranja izdelal grafičnega odjemalca, ki zna uporabljati vse tri storitve, nahaja pa se v paketu:
- tinel-gis-client
Priložen je tudi primer uporabe celobesedilnega iskanja pri storitvi geokodiranja, nahaja pa se v paketu:
- tinel-gis-geocoding-compass
Poleg lastnih paketov, sistem uporablja še naslednje zunanje knjižnice (naštete so samo najbolj pomembne):
- hibernate - jedro Hibernate
- hibernate-annotations - dodatne oznake Hibernate za preslikavo ORM
- hibernate-spatial - dodatek za prostorske podatke za Hibernate
- hibernate-spatial-postgis - narečje PostGIS za Hibernate za prostorske podatke
- spring - ogrodje Spring Framework
- jts - implementacija prostorskih podatkov in orodij po standardih OGC
Za dnevniške vnose:
- commons-logging - vsebuje vmesnike za pisanje dnevniških vnosov
- log4j - stroj za pisanje dnevniških datotek
Za potrebe testiranja pa:
- junit - ogrodje za enotsko testiranje (angl. unit testing)
- spring-test - ogrodje za integracijsko testiranje (angl. integration testing)
- easymock - pripomočki za enotsko testiranje
Testni odjemalec potrebuje še cel kup knjižnic GeoTools, ki jih potrebuje predvsem za prikaz oz. projekcijo prostorskih podatkov. Priložen primer uporabe celobesedilnega iskanja pa ogrodje Compass, ki vsebuje iskalni stroj.
Vsi trije glavni paketi se s pomočjo orodja Maven zapakirajo v tako imenovane datoteke WAR (Web Application Archive), ki vsebujejo prevod, vse potrebne knjižnice in nastavitvene podatke za neposredno poganjanje v vsebniku.
Ostali paketi so predstavljeni zgolj kot knjižnice za nadaljnjo uporabo, zato se zapakirajo v datoteko JAR (angl. Java Archive).
Vsi paketi z izvorno kodo so priloženi v projekti.zip.
5.5 Vključitev v lastni sistem
Sistem je zasnovan modularno. Če ga želimo vključiti oz. uporabiti v svojem že obstoječem ali novem sistemu, moramo na odjemalčevi strani:
- uporabiti knjižnice tinel-gis-geocoding-client, tinel-gis-reversegeocoding-client ali tinel-gis-routing-client, odvisno od tega, katero storitev potrebujemo,
- vzpostaviti HTTP Invokerja za vsako storitev posebej in
- uporabiti pripravljene metode storitev.
<!-- HTTP Invoker proxy -->
<bean id="geocodingService"
class="org.springframework.remoting.httpinvoker
.HttpInvokerProxyFactoryBean" lazy-init="true">
<property name="serviceUrl">
<value>http://localhost:9082/tinel-gis-
geocoding/remoting/GeocodingService</value>
</property>
<property name="serviceInterface">
<value>net.tinelstudio.gis.geocoding.service.GeocodingService</value>
</property>
</bean>Koda 5.8: Primer vzpostavitve HTTP Invokerja za storitev geokodiranja v obliki Springovega zrna v datoteki XML.
Ob uporabi zrna geocodingService, se bo HTTP Invoker samodejno povezal na strežniško storitev (na naslovu http://localhost:9082).
@Autowired
private GeocodingService geocodingService;
@Test
public void testGeocodingService() throws Exception {
Locator locator=...;
List<?> results=this.geocodingService.find(locator);
}Koda 5.9: Primer uporabe zrna storitve geokodiranja, ki smo ga prej definirali v Springovi datoteki XML (koda 5.8). Ustvarjanje iskalca (locator) je zaradi večje preglednosti izpuščeno.
V zgornjem primeru (koda 5.9) prepustimo Springu, da ustvari GeocodingService (z oznako @Autowired). GeocodingService je v resnici samo vmesnik (angl. interface) storitve geokodiranja, klici njegovih metod pa se prek HTTP Invokerja prenašajo na strežnik. Pred klicem metode find, je treba definirati še iskalca (locator), kar sem zaradi večje preglednosti izpustil.
Na strežniški strani moramo prilagoditi ali podatkovni model obstoječim podatkov ali podatke podatkovnemu modelu. V obeh primerih nas zanima samo knjižnica tinel-gis-model, kjer so definirane preslikave ORM in DAO. Če bomo prilagodili podatkovni model obstoječim podatkom, se bomo lotili popravljanja preslikav ORM in prilagajanja DAO, v kolikor imamo namen prilagoditi obstoječe podatke novemu podatkovnemu modelu, si bomo verjetno pripravili nekaj skript za pretvarjanje podatkov, v pomoč pa nam bo obstoječi DAO.